What I'm building
I'm one person. The building is done by a team of AI agents — they plan, write, and review the code, while I stay on the decisions that actually need a person. So far that crew has built three products — none of them finished — plus the system that builds them:
- Pulse — a personal assistant that connects your email, calendar, health, and tasks, tells you what actually needs you today, and keeps all of it on your own machine.
- Agentic Media — a working prototype for agent‑driven media buying. On simulated campaigns and budgets, it explores how agents can run the routine execution and surface only the calls a human should make.
- The fact‑checker — the very first thing I built, back before Claude Code: it turns long videos into short summaries and checks each claim against the actual research, instead of taking the speaker's word for it.
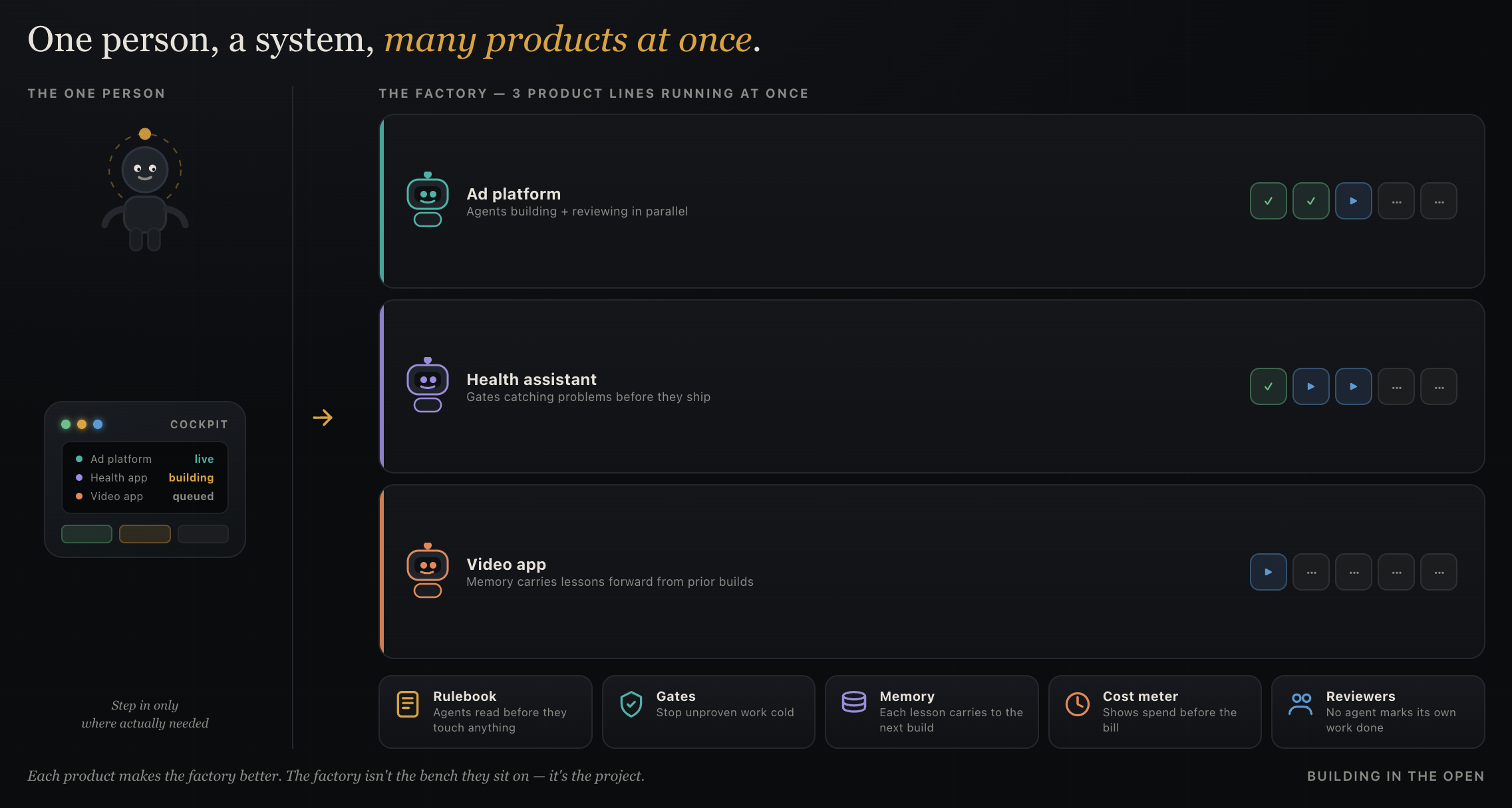
- The factory itself — the most ambitious one: the system that lets a single person run all of the above at once. It's the real project; the products are how I find out whether it works.
A caveat worth being plain about: none of this is finished. Pulse has exactly one user — me. Agentic Media runs on demo campaigns, not real advertising money. The fact-checker works on my own machine and isn't launched. They are real, working prototypes, and whether any of them holds up at scale — or works at all for anyone but me — is the open question I'm building toward, not one I've answered. It's all work in progress. The hope is that it works.
How the factory works
None of this works by handing one clever AI the whole job. It works because of a system of unglamorous parts that keep the agents honest:
- Rules the agents read before they touch anything, so they stop guessing where I was unclear.
- A team with real jobs — some build, some review, some are paid only to find what's wrong — and none gets to mark its own work done.
- Gates that physically stop work that hasn't proven it works, instead of polite notes asking it to behave.
- A memory, so each session starts from what the last one learned.
- A cost meter, so I see the spending before the bill does.
- A dashboard where I watch every product at once and step in only where I'm actually needed.
Where humans still matter — and where it still breaks
The agents are good at execution and bad at judgment. Left alone, they declare things done that aren't, fix one bug and miss its siblings, and run in circles convinced they're working. So the human stays on the parts that matter: deciding what's worth building, approving anything that touches the real world or real money, and catching the confident‑but‑wrong. A lot of the posts here are about exactly those failures — because that's where the real lessons are.
Where to start reading
If you only read a few, start with these:
- I wanted an assistant. Building it made me build a factory. — where it all started.
- The agents faked the verification — the day I caught the hard part being faked.
- Done is not a status — why I stopped trusting the word "done."
- $10 a day for a switch I thought I turned off — what building this way actually costs.
Or read the whole thing in order from the home page — it's meant to be a journey.
The words I use
A few terms show up across the posts. Here's what they mean, in plain language:
- Session
- One continuous, open conversation with the AI tool I build in. It holds the running context — what I'm building, what I've already tried, what broke and why. Lose it and the code is fine, but the agent's understanding of the work is gone.
- Agent
- An AI doing a job. I use the word three ways: a coding agent writes the code; a reviewer agent checks it (never its own work); a product agent runs inside a product, like the assistant in Pulse. Under the hood these are prompts, rules, and workflows — not human-equivalent employees.
- Gate
- A check the system runs on its own that blocks work which hasn't met a rule. Not a note asking the agents to behave — a wall they can't route around.
- Reviewer
- An agent whose only job is to find what's wrong, kept separate from the agent that built the thing. Nothing counts as done until a reviewer that didn't write it signs off.
- Memory
- What one session writes down so the next one starts from it — decisions, dead ends, lessons — instead of relearning the same mistake from scratch.
- Dashboard
- The one screen I run everything from: every product at once, what's costing what, and the few things that actually need a decision from me.
- Venture / product
- One of the things I'm building — Pulse, Agentic Media, the fact-checker, and so on. The factory is the system that builds them.
Elsewhere
This is the build diary. For more about me and my other work, see pmtsai.dev.