The demo always shows the magic. You type a sentence, the agents build the thing, everyone claps. Nobody films the part I am doing this week.
This week I am writing instructions. Not features. The rules the agents follow, the notes on what good looks like, the record of what they got wrong last time. It is slow, and none of it shows up on screen.
I started here because the agents were drifting. I would ask for one thing and get something next to it. A fix in one spot, the same bug still alive three spots over. They were guessing where I had not been clear, and they guess like anyone guesses: fast, confident, wrong.
So I stopped adding features and started sharpening the words. I write down what “done” actually means. I write down yesterday’s mistake so it does not come back tomorrow. I tell them where to stop and what to prove before they call something finished.
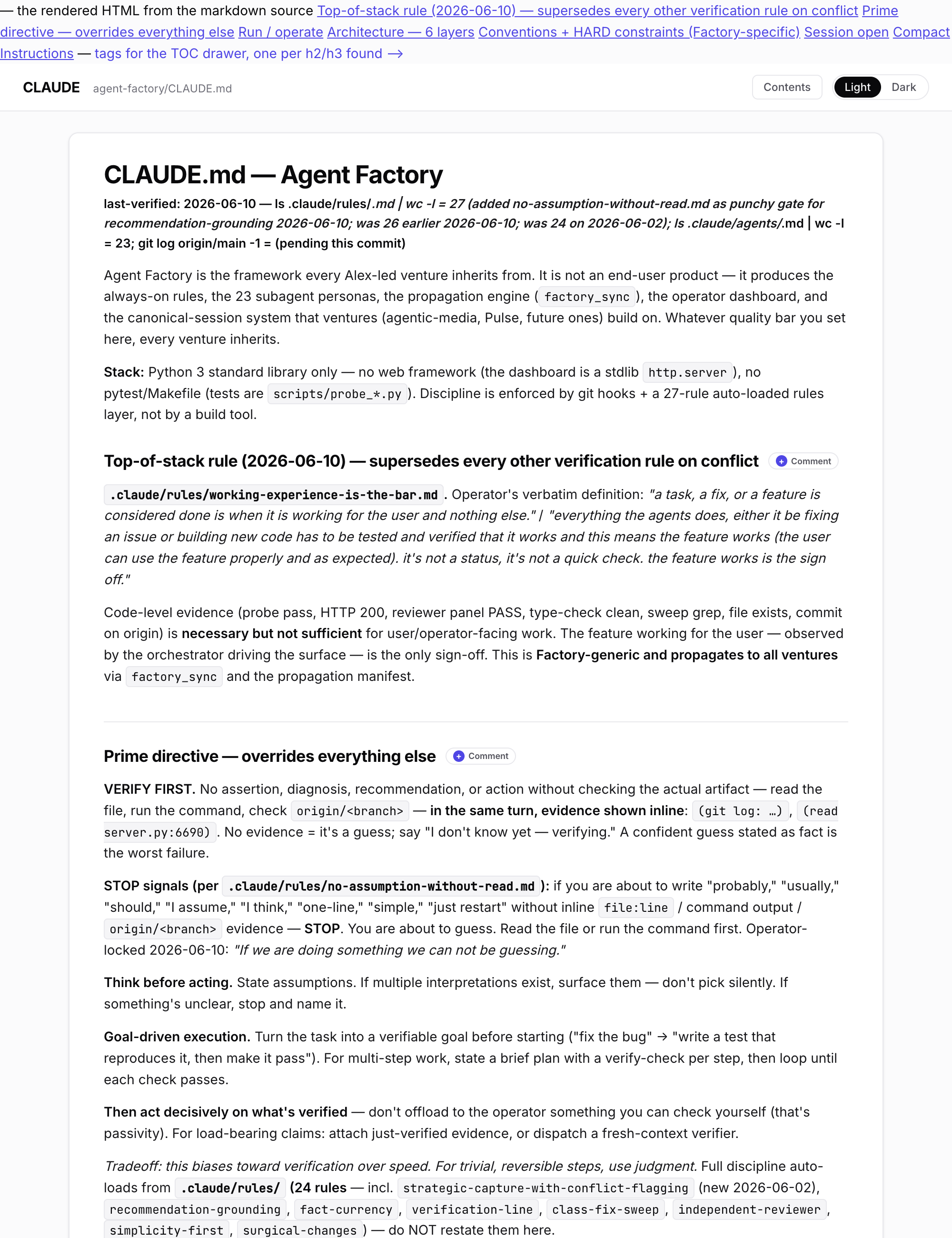
The rules read like plain sense once they exist. The work is noticing the gap in the first place, then writing the one line that closes it.
The change is not subtle. The same agents, the same model. Give them clearer words and they land the work the first time. I am not making them more powerful. I am making them less confused.
The model is a fraction of the result. The quality lives in how clearly I tell them what to do.
Hours of this. Reading what they produced, finding the gap, writing the rule that closes it. It is the least glamorous thing I do all month. It is also where the jump in quality comes from.
I keep waiting for it to feel like wasted time. It never does. There are twenty-six of these rules now, and every one of them started as a mistake I got tired of seeing twice. Each one I write once saves me the same correction a hundred times.
Learnings
I came in thinking the leverage was the model. It is not. The model was already good enough. What was missing was a clear definition of good, written down where the agents could read it, plus a memory of what they got wrong last time so they stopped repeating it.
The boring work is the high-leverage work. Writing the rules, sharpening what “done” means, capturing each lesson once. I avoided it because it is unglamorous and slow. The week I finally sat down and did it is the week the output got noticeably better, with nothing else changed.